# Algorithm
# OP frequency
# New Page
# ONNX OP statistics
## alphabet order
```
3 Abs
4325 Add
20 And
2 ArgMax
101 AveragePool
3467 BatchNormalization
3152 Cast
8 CategoryMapper
27 Ceil
407 Clip
2 Compress
2706 Concat
7714 Constant
788 ConstantOfShape
6448 Conv
2 ConvInteger
4 ConvTranspose
1 CumSum
3227 DequantizeLinear
503 Div
100 Dropout
82 DynamicQuantizeLinear
5 DynamicQuantizeLSTM
97 Equal
24 Erf
194 Exp
132 Expand
40 Flatten
52 Floor
12 FusedMatMul
7681 Gather
251 Gemm
29 GlobalAveragePool
8 Greater
2 Hardmax
91 Identity
150 InstanceNormalization
228 LeakyRelu
52 Less
1 LessOrEqual
91 Log
30 Loop
90 LRN
5 LSTM
861 MatMul
96 MatMulInteger
2 Max
522 MaxPool
4 Min
3536 Mul
3 Neg
688 NonMaxSuppression
843 NonZero
41 Not
4 OneHot
160 Pad
234 Pow
100 PRelu
1 preprocess
276 QLinearAdd
5 QLinearAveragePool
67 QLinearConcat
1191 QLinearConv
4 QLinearGlobalAveragePool
72 QLinearLeakyRelu
30 QLinearMatMul
62 QLinearMul
10 QLinearSigmoid
1577 QuantizeLinear
7 Range
100 Reciprocal
6 ReduceMax
466 ReduceMean
65 ReduceMin
8 ReduceSum
4794 Relu
2397 Reshape
43 Resize
48 RoiAlign
2 Round
2 Scan
12 Scatter
36 ScatterElements
2229 Shape
90 Sigmoid
2276 Slice
230 Softmax
135 Split
274 Sqrt
1700 Squeeze
879 Sub
249 Sum
146 Tanh
47 Tile
60 TopK
1469 Transpose
7973 Unsqueeze
22 Upsample
15 Where
```
## Frequency order
```
1 CumSum
1 LessOrEqual
1 preprocess
2 ArgMax
2 Compress
2 ConvInteger
2 Hardmax
2 Max
2 Round
2 Scan
3 Abs
3 Neg
4 ConvTranspose
4 Min
4 OneHot
4 QLinearGlobalAveragePool
5 DynamicQuantizeLSTM
5 LSTM
5 QLinearAveragePool
6 ReduceMax
7 Range
8 CategoryMapper
8 Greater
8 ReduceSum
10 QLinearSigmoid
12 FusedMatMul
12 Scatter
15 Where
20 And
22 Upsample
24 Erf
27 Ceil
29 GlobalAveragePool
30 Loop
30 QLinearMatMul
36 ScatterElements
40 Flatten
41 Not
43 Resize
47 Tile
48 RoiAlign
52 Floor
52 Less
60 TopK
62 QLinearMul
65 ReduceMin
67 QLinearConcat
72 QLinearLeakyRelu
82 DynamicQuantizeLinear
90 LRN
90 Sigmoid
91 Identity
91 Log
96 MatMulInteger
97 Equal
100 Dropout
100 PRelu
100 Reciprocal
101 AveragePool
132 Expand
135 Split
146 Tanh
150 InstanceNormalization
160 Pad
194 Exp
228 LeakyRelu
230 Softmax
234 Pow
249 Sum
251 Gemm
274 Sqrt
276 QLinearAdd
407 Clip
466 ReduceMean
503 Div
522 MaxPool
688 NonMaxSuppression
788 ConstantOfShape
843 NonZero
861 MatMul
879 Sub
1191 QLinearConv
1469 Transpose
1577 QuantizeLinear
1700 Squeeze
2229 Shape
2276 Slice
2397 Reshape
2706 Concat
3152 Cast
3227 DequantizeLinear
3467 BatchNormalization
3536 Mul
4325 Add
4794 Relu
6448 Conv
7681 Gather
7714 Constant
7973 Unsqueeze
```
# Model Compression
Model compression techniques are mainly classified into quantization (Zafrir et al.,2019), pruning (Hoefler et al., 2021; Vadera and Ameen, 2022), Neural Architecture Search(NAS) (Sun et al., 2019), and knowledge distillation
# Model Quantization
## Quantization Granularity
Quantization is a magic spell to reduce the memory footprint of a model. But often quantization leads to a drop in the accuracy of the model. This is where the Granularity of quantization comes into the picture. Selecting the right granularity helps in maximizing the quantization without much drop in the accuracy performance
### Per-Tensor Quantization
In per-tensor quantization, the same quantization parameters are applied to all elements within a tensor. Applying the same parameters across tensors will cause a drop in accuracy.
### Per-Channel Quantization
In per-channel quantization, different quantization parameters are applied to each channel of a tensor independently. This often leads to a lower error while quantizing compared to per tensor quantization.
Per-channel quantization captures variations in different channels more accurately. This usually helps in CNN models where the range of weights varies over different channels.
[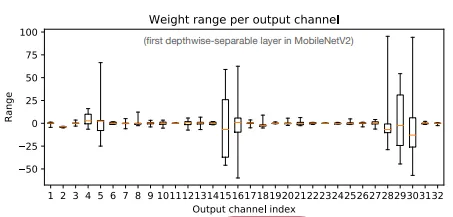](https://fgpu.tech/uploads/images/gallery/2025-02/image.png)
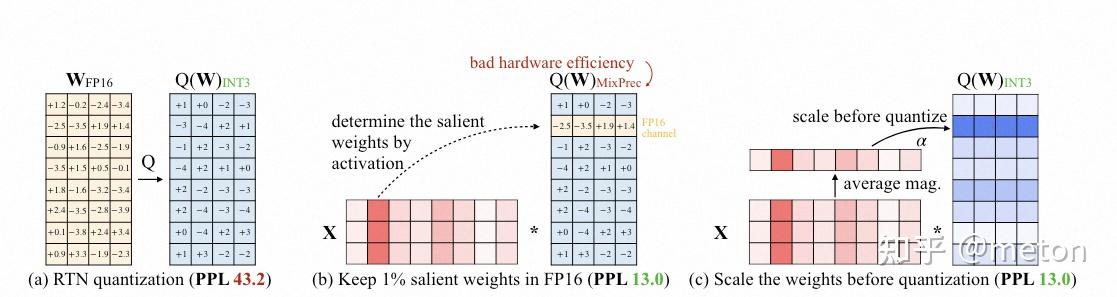
### Mix-precision Quantization
different layer using different precision.
## Quantization Method
[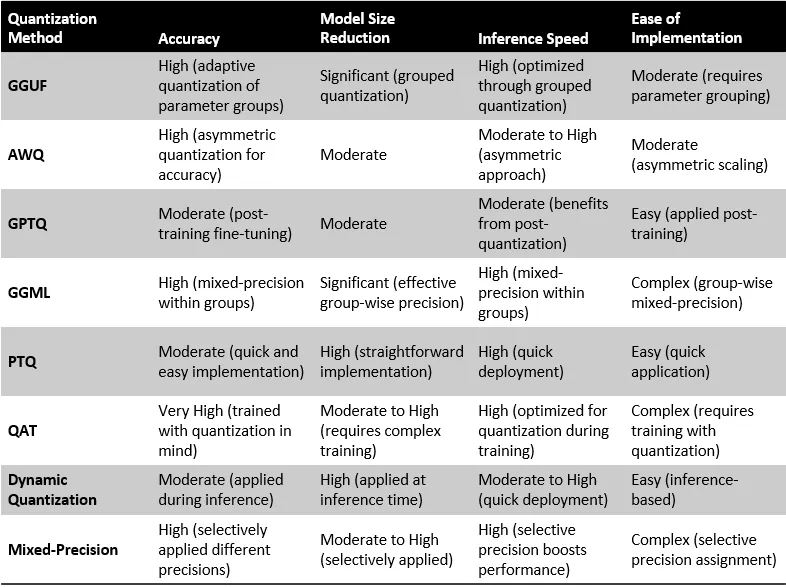](https://fgpu.tech/uploads/images/gallery/2025-02/674image.png)
# Neural Arch Search
# Knowledge Distillation
# Pruning
# reference
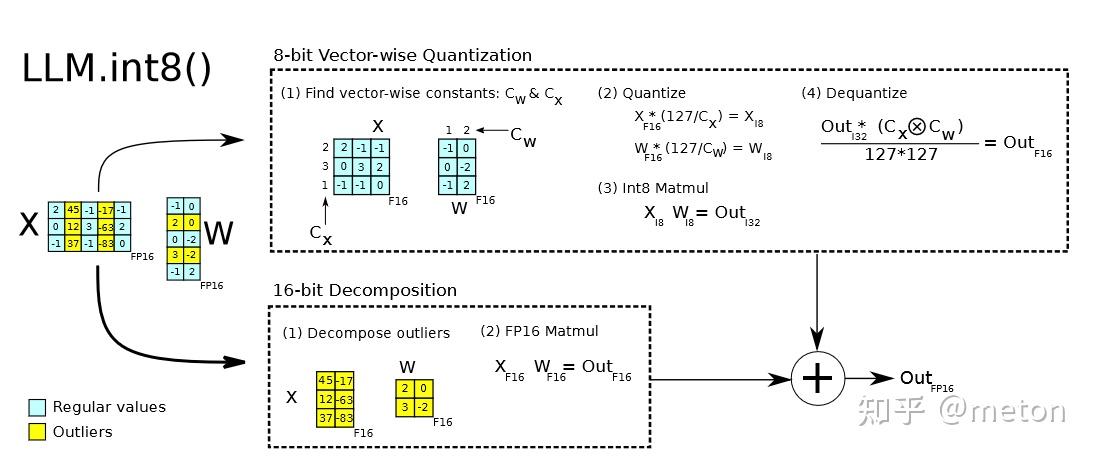
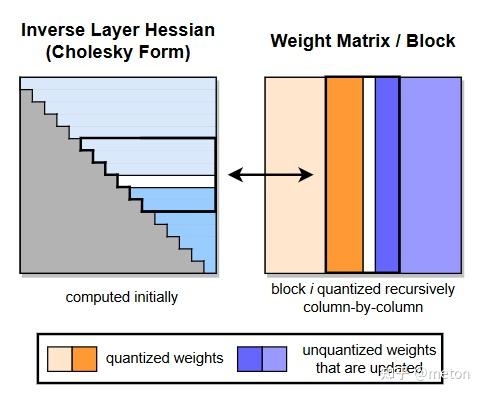
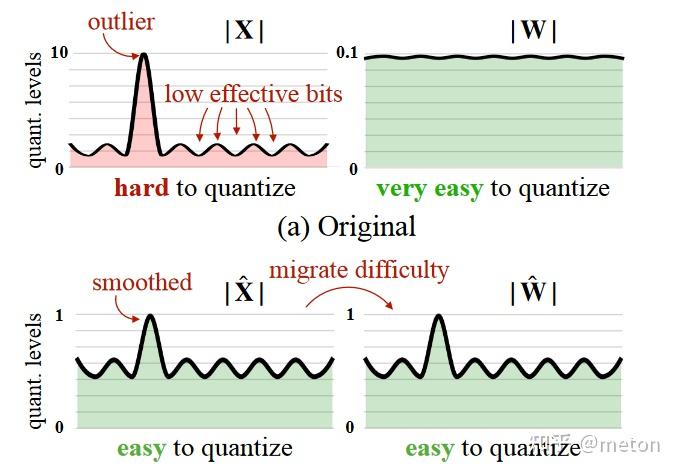
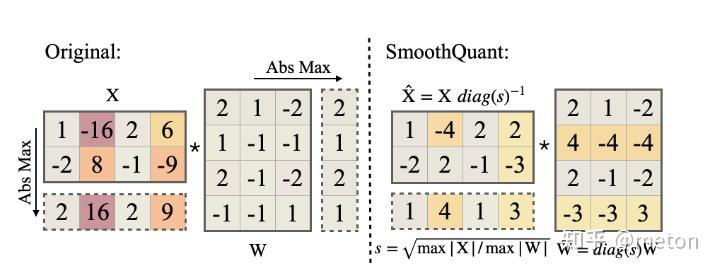
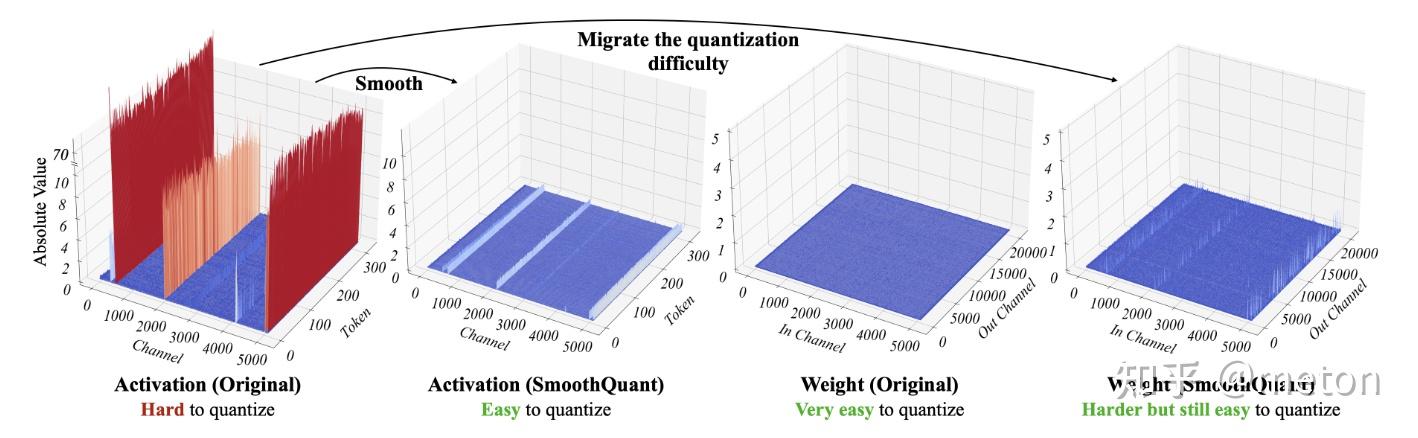
## 量化技术背景
### 从CNN量化说起
在传统CNN网络中,为了加速网络的推理速度,一种非常有效的方法是[INT8量化
x f s c a l e " id="bkmrk--2" role="presentation" tabindex="0">x q 
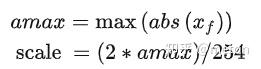



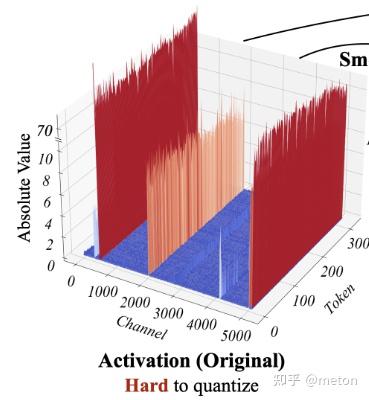

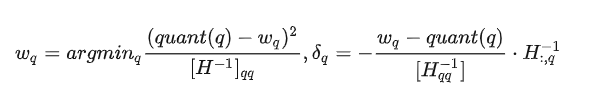



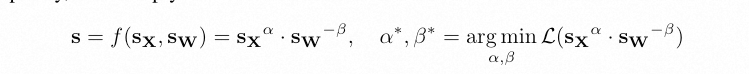

Δ W A B = Δ W