Model Quantization
Quantization Granularity
Quantization is a magic spell to reduce the memory footprint of a model. But often quantization leads to a drop in the accuracy of the model. This is where the Granularity of quantization comes into the picture. Selecting the right granularity helps in maximizing the quantization without much drop in the accuracy performance
Per-Tensor Quantization
In per-tensor quantization, the same quantization parameters are applied to all elements within a tensor. Applying the same parameters across tensors will cause a drop in accuracy.
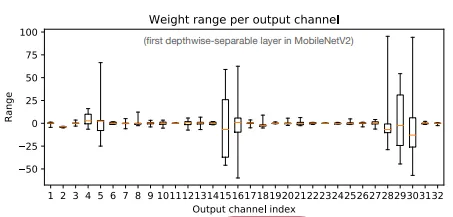
Per-Channel Quantization
In per-channel quantization, different quantization parameters are applied to each channel of a tensor independently. This often leads to a lower error while quantizing compared to per tensor quantization.
Per-channel quantization captures variations in different channels more accurately. This usually helps in CNN models where the range of weights varies over different channels.
Mix-precision Quantization
different layer using different precision.
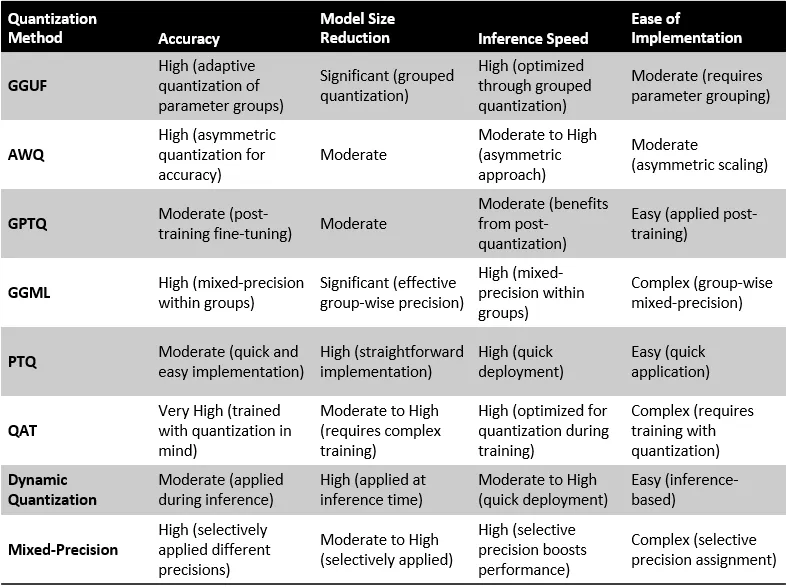
Quantization Method
No Comments